Installing and Configuring Elasticsearch
This document provides reference information and examples relating to installation and configuration of the Elasticsearch search feature for the Akana API Platform Community Manager developer portal.
Note: For information about secure configuration of Elasticsearch, see Configuring Elasticsearch with security.
On this page:
Elasticsearch feature overview:
- About the Elasticsearch feature
- Elasticsearch version
- System requirements
- Planning your Elasticsearch feature
- REST Client Deployment mode
- Links to additional information about Elasticsearch
Installing and Configuring Elasticsearch:
- Installing Elasticsearch
- High-level steps for Elasticsearch configuration
- What changes do I need to make to the Elasticsearch YAML file?
- How do I configure Elasticsearch?
- How do I configure the number of nodes and shards?
- Updating the Elasticsearch index
- Using Elasticsearch with AWS NLB: Enabling TCP keepalive values (2020.2.18 and later)
Elasticsearch feature information:
About the Elasticsearch feature
Elasticsearch is a search engine based on Apache Lucene. It is robust, and allows fast indexing and responsive updating. It's an extremely popular tool in very broad use—a scalable search solution that uses JSON messaging over an HTTP interface with a native Java API.
Elasticsearch is run in standalone mode. Your installation will need to have Elasticsearch installed on at least one server. Just as with a relational database, you'll need to provide the software and hardware required. You can get started with a trial license.
All containers running the Akana API Platform can use Elasticsearch. A cluster is recommended for redundancy.
Deployment is via REST Client.
Administration of Elasticsearch is done with the configuration wizard in the Akana Administration Console.
For more information on Elasticsearch terminology, refer to the Elasticsearch glossary: https://www.elastic.co/guide/en/elasticsearch/reference/current/glossary.html.
Elasticsearch version
For the latest information about supported Elasticsearch versions, refer to the System Requirements doc, Elasticsearch section.
System requirements
For system requirements for the standalone Elasticsearch server, refer to the correct version of the platform system requirements document, as listed in Elasticsearch version.
Planning your Elasticsearch feature
As part of planning your installation, you'll need to make some decisions about how you want to set up the Elasticsearch feature:
- Do you want one or more Elasticsearch servers? Additional servers are recommended, for fallback reasons.
- Do you want dedicated Elasticsearch servers? You could also install Elasticsearch on one or more servers running the Akana API Platform.
-
Use the REST Client deployment mode, see REST Client mode.
REST Client mode
The REST Client communicates to the Elasticsearch server or cluster by accessing a URL. Introduced in a recent version of Elasticsearch.
Links to additional information about Elasticsearch
For more information about Elasticsearch, refer to the following:
- Elasticsearch website: https://www.elastic.co/
- Configuring Elasticsearch with Security (specific to Akana)
- Elasticsearch glossary: https://www.elastic.co/guide/en/elasticsearch/reference/current/glossary.html
Installing and configuring Elasticsearch:
Installing Elasticsearch
You'll need to download Elasticsearch, and install it on the server or servers you'll be using. To determine the version to install, see Elasticsearch version.
Follow the instructions provided by Elasticsearch.
Download file locations:
- 8.5.3: https://www.elastic.co/downloads/past-releases/elasticsearch-8-5-3.
- 7.14.2: https://www.elastic.co/downloads/past-releases/elasticsearch-7-14-2.
High-level steps for Elasticsearch configuration
To use Elasticsearch on the Akana API Platform you'll need to:
- Install Elasticsearch on one or more servers. See Installing Elasticsearch.
- As part of the Elasticsearch installation, modify the Elasticsearch YAML file. See What changes do I need to make to the Elasticsearch YAML file?
- Optional: set up security for your Elasticsearch, which requires additional setup and additional modifications to the Elasticsearch YAML file. See Configuring Elasticsearch with Security.
- Complete the global configuration steps, once for all containers. See How do I configure Elasticsearch?
- Create an app to generate the index for the first time.
What changes do I need to make to the Elasticsearch YAML file?
You'll need to make some changes to one of the Elasticsearch configuration files, elasticsearch.yml, so that Elasticsearch will work for your Akana API Platform installation.
The elasticsearch.yml file is generally stored in the {elasticsearch_home}/config folder. It might have some default placeholder content, but not all the placeholder values.
As a starting point to model your changes, you can use the example in Sample Elasticsearch YAML file.
Note: If you want security, you'll need to add some extra values, using the example in Sample Elasticsearch YAML file with security settings. If you don't want security, just set up the values listed below.
- Cluster name: needed for REST Client. For example:
cluster.name: akana
- Node name: needed for REST Client, if you want to name your own node. For example:
node.name: node-1
- Path to directory where to store the data. For example:
path.data: /path/to/data
- Optional if you don't want to bind to all interfaces: Set the bind address to a specific IP. For example:
network.host: 192.168.0.1
- Pass an initial list of hostnames for all the nodes in the cluster, to provide a seed list of other nodes in the cluster that are likely to be live and contactable, as part of discovery. See Discovery Settings on the Elasticsearch website. For example:
discovery.zen.ping.unicast.hosts: ["localhost", "[::1]"]
- Increase the default configuration value for the maximum number of Boolean clauses allowed within a search string. This property is deprecated as of Elasticsearch 8.x. It is now dynamically calculated based on the size of the search thread pool and the size of the heap allocated to the JVM. See Search Settings on Elasticsearch website. For example:
indices.query.bool.max_clause_count: 10000
For more information on this setting, see Search Settings (Elasticsearch documentation).
For general information about the elasticsearch.yml file, see https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html.
Sample Elasticsearch YAML file
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # cluster.name: akana # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # node.name: node-1 # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # path.data: /path/to/data # # Path to log files: # path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # By default Elasticsearch is only accessible on localhost. Set a different # address here to expose this node on the network: # # network.host: 192.168.0.1 # # By default Elasticsearch listens for HTTP traffic on the first free port it # finds starting at 9200. Set a specific HTTP port here: # http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # #discovery.seed_hosts: ["host1", "host2"] # # Bootstrap the cluster using an initial set of master-eligible nodes: # #cluster.initial_master_nodes: ["node-1", "node-2"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true # # ---------------------------------- Security ---------------------------------- # # *** WARNING *** # # Elasticsearch security features are not enabled by default. # These features are free, but require configuration changes to enable them. # This means that users don’t have to provide credentials and can get full access # to the cluster. Network connections are also not encrypted. # # To protect your data, we strongly encourage you to enable the Elasticsearch security features. # Refer to the following documentation for instructions. # # https://www.elastic.co/guide/en/elasticsearch/reference/7.16/configuring-stack-security.html
Note: If you want to use security with Elasticsearch, you'll need to set up additional values in the YAML file. See Sample Elasticsearch YAML file with security settings.
Default ports for Elasticsearch configuration
The default ports for Elasticsearch configuration is HTTP: Default is 9200, default range is 9200–9299. Range implies that if the first port is busy, the platform tries the next one and so on.
How do I configure Elasticsearch?
In configuring the Elasticsearch feature for your Akana API Platform implementation, you'll need to do the following:
- Follow the applicable set of steps for the REST Client deployment mode.
- Create an app to generate the index for the first time
Note: Configuration needs to be set up only once, for all containers, and can be done in any one container. The settings are stored in the database for the entire implementation.
Configure Elasticsearch Global Configuration: REST Client
- In the Akana Administration Console, on the Tasks tab, under All, choose Configure Elasticsearch Global Configuration. The wizard opens.
- For Deployment Mode, choose REST Client.
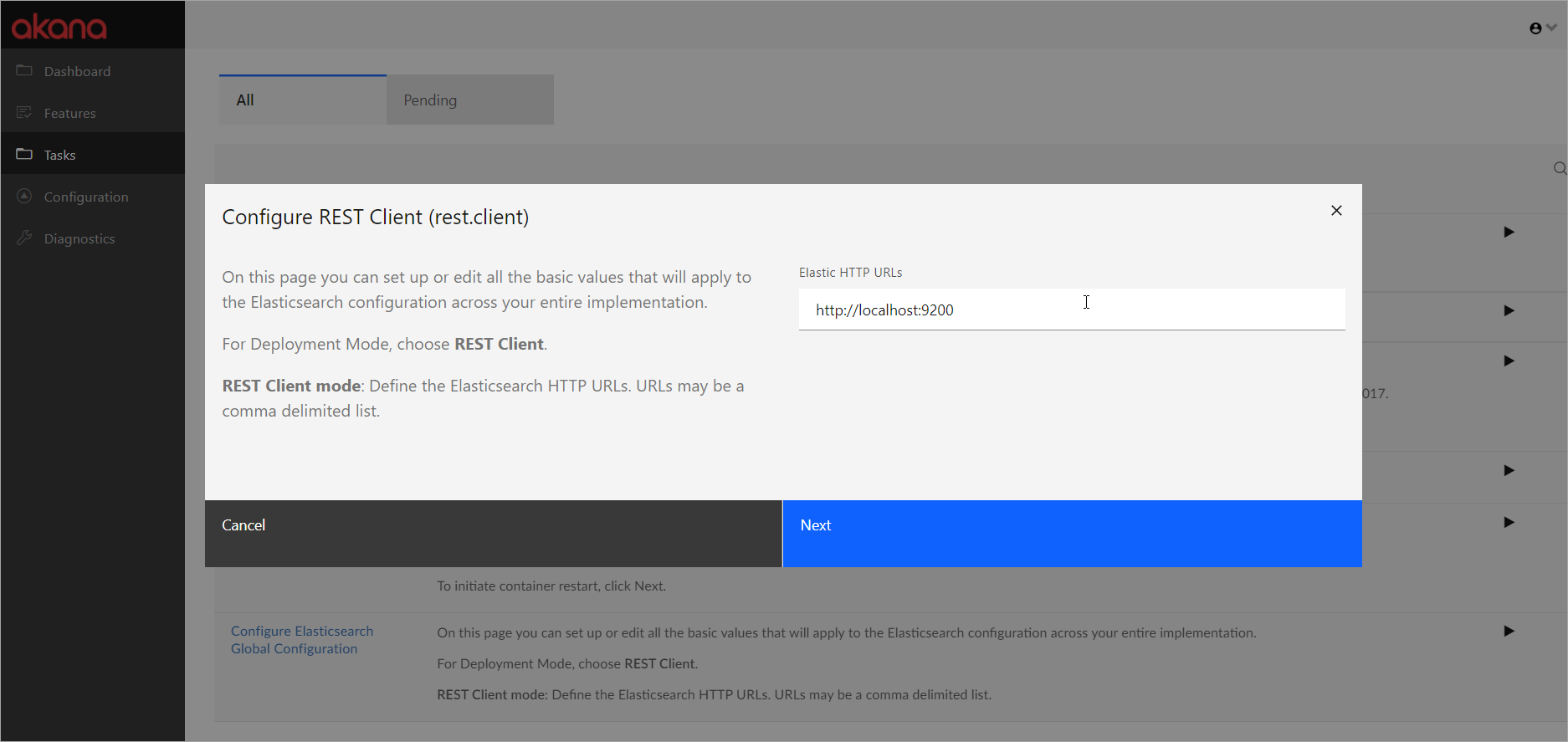
- In the Elastic HTTP URLs field, provide the HTTP URLs for each container where Community Manager is running, as well as any container running scheduled jobs. Provide full URLs; use a comma separator between values. Examples:
- http://localhost:9200
- https://localhost:9200
- http://localhost:9200,http://localhost:9250
Note: If there are multiple URLs, the protocol must be the same for all. For example, you cannot mix HTTP and HTTPS.
- Click Next to complete the Elasticsearch configuration.
Create an app to generate the index for the first time
When you've completed the configuration, the index isn't generated until you create some content to be indexed.
When you first log in to the Community Manager developer portal after configuring, you'll see a General Search Error until the first index is generated.
To resolve this, create an app in the Community Manager developer portal. This causes the first index to be generated. After that, the search error is resolved and adding and indexing of content can proceed as normal.
For instructions on creating an app in the Community Manager developer portal, see How do I add an app? (Community Manager developer portal help).
How do I configure the number of nodes and shards?
Note: This step is optional. The platform defaults are sufficient.
The platform includes configuration settings that you can use to manage your Elasticsearch setup. These are controlled by configuration settings in the Akana Administration Console.
In the Akana Administration Console, the configuration category is: com.akana.elasticsearch.
In the default configuration, shown below, there are two shards and one replica. Let's say there are two nodes in the cluster. One shard, approximately half the index, is stored on each node. The one replica includes a replica of each shard:
- Node 1 has Shard 1 and the replica of Shard 2
- Node 2 has Shard 2 and the replica of Shard 1
In this scenario, if one node goes down, the other node has the full search index. Additional nodes add additional safety.
There are two settings, as shown below.
- elastic.config.index.number.of.replicas
- The number of replicas (additional copies) of the Elasticsearch index. Each replica includes a replica of each shard, so one replica might be distributed across multiple nodes, just as the index itself is split into shards which are distributed across nodes.
- Default: 1
- elastic.config.index.number.of.shards
- The number of shards (splits) for the Elasticsearch index.
- Note: This is a one-time setting. An Elasticsearch index cannot be re-sharded; if you want to change the number of shards, after changing the setting you'll need to delete the /index folder that the search index is stored in and then rebuild the index.
- Default: 2
For additional information about configuration settings in the Akana Administration Console, see Admin Console Settings.
Updating the Elasticsearch index
New in version: 2020.2.0
From time to time, as new features are added to the Community Manager developer portal, additional fields are added to the Elasticsearch index.
In version prior to 2020.2.0, when new fields were added, it was necessary to run specific commands, and then a database query, to update the Elasticsearch index.
In 2020.2.0 and later, if new Elasticsearch indexes are added, you can run an automation recipe, cm-es-index-upgrade.json, to update the index. This recipe takes no parameters.
In addition, the upgrade recipe for the Community Manager developer portal, cm-upgrade.json, calls the cm-es-index-upgrade.json recipe, so that the Elasticsearch index is updated if needed.
If you're upgrading to a new minor version, and new fields have been added to the Elasticsearch search index, as specified in the Release Notes, run the cm-es-index-upgrade.json recipe to ensure that the additional values appear in the Community Manager developer portal search index.
Using Elasticsearch with AWS NLB: Enabling TCP keepalive values
Valid in Version: 2020.2.18 and later
If you're using Elasticsearch on Amazon Web Services (AWS) with the AWS NLB load balancer, you'll need to update the keepalive settings on any servers that Akana containers using Elasticsearch are running on; essentially, any container that has Policy Manager or Community Manager installed. By default, the AWS NLB closes connections after 350 seconds. In practical terms, if a Community Manager user does a search, gets the results, then does something else for more than 350 seconds and then searches again, there will be an error because the connection was closed by the load balancer. In this scenario, of course the user can do the search again and get the search results.
To prevent this occurring, in 2020.2.18 and later, for all Akana containers that have Policy Manager or Community Manager installed, the Elasticsearch Java API Client is configured with the setSoKeepAlive property set to true.
When this property is set to true, you can make changes to the Linux server configuration, for any Akana servers that are using Elasticsearch (Policy Manager or Community Manager containers). For information about the TCP keepalive settings, refer to the article titled Enable TCP keepalives by default in Java REST clients: https://github.com/elastic/elasticsearch/issues/65213a. The three settings you might choose to configure are:
- net.ipv4.tcp_keepalive_time (default = 7200 seconds which is 2 hours). If you set this value to 300 it will be activated before the 350 second AWS NLB interval expires.
- net.ipv4.tcp_keepalive_intvl (default = 75)
- net.ipv4.tcp_keepalive_probes (default = 9)
For additonal information, refer to:
- Definitions for the keepalive settings: https://tldp.org/HOWTO/TCP-Keepalive-HOWTO/usingkeepalive.html
- Information about the Elasticsearch Java API Client: https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/7.17/index.html