Using Kafka
Provides information about Kafka implementation, including benefits, installation, and configuration.
Valid in Version: 2020.1.1 and later
On this page:
- Overview
- Advantages of Kafka implementation with the Akana Platform
- Kafka Deployment Recommendations
- Installing Apache Kafka for testing purposes
- Installing Akana Kafka features
- Configuration Properties for Kafka
- Topic Configuration
Overview
The Akana Platform offers the option to use Kafka as an alternative for streaming audit data. If you have an implementation that's high-volume, with many or very large messages, you can use Kafka to more efficiently manage the traffic flow to help ensure the load on the API Gateway remains manageable. Audit data is channeled through Kafka and is then persisted through the RDBMS or in MongoDB. In general, the Gateway produces data into Kafka. Consumer containers will then, in turn, read the data.
Kafka is noted for its capabilities to support high throughput, scalability, safe storage of streams of data in a distributed and fault-tolerant cluster, and high availability across distributed clusters and geographical regions. It supports scalability with fault tolerance for heavy-traffic systems. Kafka is distributed, partitioned, and highly fault-tolerant.
Using Kafka as part of the API Platform requires separate installation and configuration of Kafka itself, including hardware requirements. See Installing Akana Kafka features.
You also have the option, as part of your Kafka implementation, to use Elasticsearch for temporary storage of large messages. See Claim Check pattern (with Detailed Auditing policy) below.
For general information about Kafka, see https://kafka.apache.org/ (external site).
Advantages of Kafka implementation with the Akana Platform
By using Kafka in your implementation, you can benefit from the additional data processing capabilities of Kafka. Practical benefits:
- Reduction of memory load on the Gateway—Help reduce the possibility of out of memory (OOM) problems with the Gateway. Using Kafka helps reduce memory load on the Gateways by moving usage data, particularly recorded messages, out of memory in a more timely manner.
- Reduction of potential impact on other containers—In-memory usage data and metric data causing out of memory issues on the Gateways could also impact the Policy Manager containers which are the consumers of the data.
- Safety of usage data—Helps prevent loss of usage data. Because of limitations relating to the synchronous REST APIs used to report usage and metrics, loss of usage data is possible in times of high volume. Of course, usage data is critical. Using Kafka is a way to implement a more efficient configuration, in scenarios where loss of critical usage data might be a possibility because of high volume and/or limited resources.
- Kafka can help balance load in terms of CPU, memory, and persistent storage management across the system. For example, a pull model such as Kafka for usage data in Policy Manager allows for a more even load profile than the default push model through REST APIs.
- Using Kafka can help reduce stress on both Gateway containers and Policy Manager containers. The availability and health of the Policy Manager containers is essential for the success of the Gateways.
- Using Kafka, you can use a percentage of the Heap instead of an arbitrary queue size number (the maximum number of messages that can be queued) for usage messages/bulk data.
Kafka Deployment Recommendations
In this section:
- Supported versions
- Brokers
- Zookeeper instances
- Consumer instances
- Partitions
- Replication factor
- Disk allocation
- Monitoring
- Cross-region mirroring
Supported versions
For Kafka supported version, go to the System Requirements doc. Then, go to the Kafka version section.
Brokers
Recommendation: a minimum of 3 brokers with 4 vCPU and 16GB RAM each.
Zookeeper instances
Recommendation: a minimum of 3 Zookeeper instances with 2 vCPU and 8GB RAM each.
Consumer instances
Recommendation: a minimum of 3 consumer instances with 4 vCPU and 16GB RAM each.
The number of consumers is usually proportionate to the number of partitions. The consumer instances should be increased based on the throughput that the Gateway containers are generating, so that the consumer throughput is balanced with the producer throughput.
Partitions
In general, use three times as many partitions as there are Gateways/producers. This is dependent on the number of consumer nodes (see above). A rule of thumb formula:
Number of partitions >= ND * 3
For recommendations and formulas, refer to the Kafka documentation: https://kafka.apache.org/documentation/.
Replication factor
The maximum replication factor is:
Number of replicas <= number of brokers
For example, in an environment with three brokers, two replications are recommended.
For more information, refer to the Kafka documentation, Replication section: https://kafka.apache.org/documentation/#replication.
Disk allocation
Recommendation:
- General purpose SSD
- 10 MB/s data flow
- Disk size should be allocated according to retention time and usage.
Monitoring
In any production deployment it is expected that there will be a system-wide monitoring of Kafka.
Cross-region mirroring
Cross-region mirroring (replication) is out of scope in the current implementation of Kafka.
Installing Apache Kafka for testing purposes
You might want to install a single-broker Kafka on a standalone container, locally, perhaps for testing purposes. Of course for a production environment you would need more, but for testing purposes you could set up Kafka using the Apache Kafka Quickstart Guide: http://kafka.apache.org/quickstart.
Installing Akana Kafka features
You'll need to install Kafka features in each container:
In each container, install the following features, available in the Akana Administration Console: Available Features > Plug-In:
- Akana Kafka Support for Network Director
- Akana Kafka Support for Policy Manager
Installing Kafka in the Network Director container
The Network Director writes to Kafka.
In each Network Director container, install the Akana Kafka Support for Network Director feature. Follow the steps below.
To install Kafka on the Network Director container
- Log in to the Akana Administration Console for the Network Director container.
- Go to the Available Features tab and then, at the Filter drop-down on the right, click Plug-In.
- Check the box next to the Akana Kafka Support for Network Director feature and click Install Feature.
- At the Resolution Report page, click Install Feature.
- At the Installation Complete page, click Configure. The Configure Kafka Brokers for Auditing page appears, as shown below.
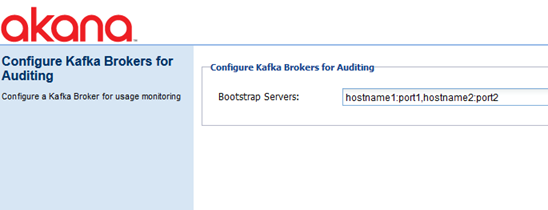
- Enter the information needed for Network Director to connect to the Kafka Brokers. Note:
- Format is {hostname}:{port}. For example, localhost:9092.
- For multiple bootstrap servers, use a comma separator. For example, hostname1:9092,hostname2:9093,hostname3:9094.
- Click Finish.
- At the prompt, restart the system.
The next step is to turn on the Kafka writers.
Installing Kafka in consumer containers
The Consumer container (Policy Manager or Community Manager) reads from Kafka.
In each Policy Manager or Community Manager container, install the Akana Kafka Support for Policy Manager feature. Follow the steps below.
To install Kafka on a Policy Manager or Community Manager container
- Log in to the Akana Administration Console for the consumer container.
- Go to the Available Features tab and then, at the Filter drop-down on the right, click Plug-In.
- Check the box next to the Akana Kafka Support for Policy Manager feature and click Install Feature.
- At the Resolution Report page, click Install Feature.
- At the Installation Complete page, click Configure. The Configure Kafka Brokers for Auditing page appears. For an illustration, see above.
- Enter the information needed for the consumer container to connect to the Kafka Brokers. Note:
- Format is {hostname}:{port}. For example, localhost:9092.
- For multiple bootstrap servers, use a comma separator. For example, hostname1:9092,hostname2:9093,hostname3:9094.
- Click Finish.
- At the prompt, restart the system.
The next step is to turn on the Kafka readers on each consumer container.
Configuration Properties for Kafka
When you install the Kafka feature, either in a Network Director container or a Policy Manager or Community Manager container, additional configuration properties become available, as shown below.
In the Akana Administration Console for the container, click the Configuration tab.
These two sets of configuration properties affect Kafka:
Configuration category: com.akana.kafka
The three values shown below are set when you install the Kafka feature.
In this configuration category, you can add additional properties and values supported by Kafka. There are many supported configuration properties, as covered in the Apache Kafka documentation, Configuration section: https://kafka.apache.org/documentation/#configuration.
For example, you could add the acks property to configure "the number of acknowledgments the producer requires the leader to have received before considering a request complete," along with min.insync.replicas to specify "the minimum number of replicas that must acknowledge a write for the write to be considered successful." Or you could add the ssl.truststore.location and ssl.truststore.password properties to set up a trust store.
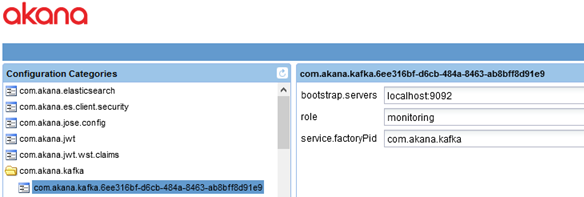
- bootstrap.servers
- The address for the bootstrap servers, which you set up as part of installing the Kafka feature. This is the bootstrap.servers Kafka configuration property. Format is {hostname{:{port}, with comma separators for multiple values. For an example see To install Kafka on the Network Director container, or refer to the Kafka documentation for the bootstrap.servers property: https://kafka.apache.org/documentation/#bootstrap.servers.
- role
- The role of Kafka in this instance. Defaults to monitoring, the only valid value.
- service.factoryPid
- Defaults to the configured value.
Configuration category: com.akana.monitor.kafka
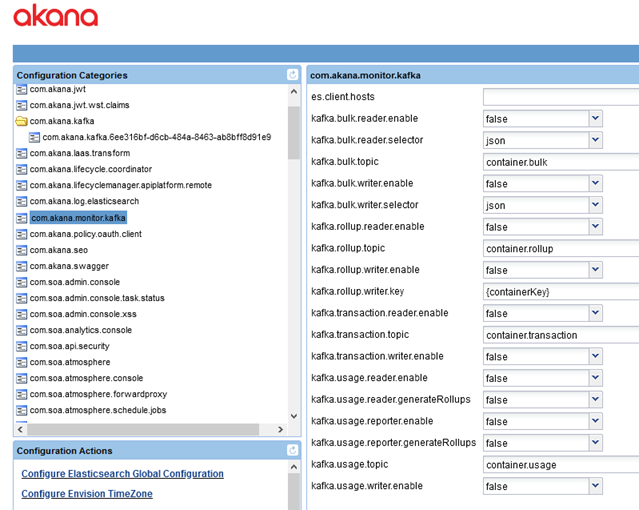
Set the following properties:
- reader values:
- For the Policy Manager and Community Manager containers, or any other Akana Kafka consumer container, set the value for all four reader properties to true:
- kafka.bulk.reader.enable
- kafka.rollup.reader.enable
- kafka.transaction.reader.enable
- kafka.usage.reader.enable
- writer values
- For the Network Director containers, set the value for all four writer properties to true:
- kafka.bulk.writer.enable
- kafka.rollup.writer.enable
- kafka.transaction.writer.enable
- kafka.usage.writer.enable
Configuration
In this section:
- Topic Configuration
- Server Configuration and Trust Store
- Claim Check pattern (with Detailed Auditing policy)
Topic Configuration
When you install the Kafka feature, the platform includes recommended topic names. If you accept these recommendations, no other Kafka usage configuration is needed.
If you choose to use different topic names, you'll need to update the configuration on all Gateways and on all containers on which the Akana Kafka Consumers feature is installed.
The default topic names are:
- container.usage
- container.bulk
- container.rollup
- container.transaction
You'll need to create these topics in the Broker as part of setup, using the Create Topic script: see http://kafka.apache.org/quickstart, Step 3, Create a Topic to Store Your Events.
Server Configuration and Trust Store
For information about the server configuration and trust store properties, refer to the Apache Kafka documentation, Configuration section: https://kafka.apache.org/documentation/#configuration.
You can add these properties in the com.akana.kafka configuration. See Configuration category: com.akana.kafka.
Claim Check pattern (with Detailed Auditing policy)
The Akana Platform Kafka implementation allows you to use Elasticsearch for temporary storage of large messages ("claim check" system) to help optimize traffic handling and ease the burden on the Gateway. The message body and headers are stored in Elasticsearch, with a unique ID. The only data that is indexed is the ID; message and header content are not indexed, which means that the message size does not increase the processing burden significantly. If you use the Detailed Auditing policy on your messages, with a record size (payload and header) exceeding 20 KB, you might choose this option. However, note that we do not recommend using the Detailed Auditing policy habitually in a runtime environment because of the increased load to the system. In most cases, the Basic Auditing policy is all that's needed.
Note: This Elasticsearch implementation is separate from the Elasticsearch implementation used for indexing in the Community Manager developer portal.
To enable Elasticsearch for use with Kafka
Follow the steps below for each container that is running Kafka.
- Log in to the Akana Administration Console for the container.
- Click the Configuration tab and then, under Configuration Categories, go to com.akana.monitor.kafka.
- Change the value of the kafka.bulk.writer.selector property from json to elastic.
- In the es.client.hosts property, provide the Elasticsearch host in the format http://{hostname}:{port). For example: http://localhost:9200.
- Click Finish.